









Why old school data lakes were more like data puddles
After working for many years on building Data Warehousing solutions on-prem, I wondered how a Data Lake could help businesses design and implement a Data Warehouse on the cloud.
Well, if you were building a Data Warehouse (DW) using the good old Kimball approach, you were in for quite a complex ride. Why? Simply because Data Lake file formats lacked the ability to perform 2 elementary things from the database world:
1) UPDATE, MERGE, Delete like in ANSI SQL
2) ACID (atomicity, consistency, isolation and durability)
Without those two basic capabilities, things like building Type 1, or 2 dimensions were out of the equation. Why?
How could I/You update a field in a dimension? How could I retain a surrogate key? How would I rewrite all the Foreign Keys in my Fact tables?
Without the ability to UPDATE or MERGE, building type 1 or 2 dimensions seemed like a mission fit for John Rambo. But here’s the twist; even Rambo would find this task challenging without the right tools. Sure, with brute force, you might manage to rebuild the dimensions and fact tables from scratch during a daily batch load. Or opt for creating a wide column table, but let’s face it – that’s a resource-intensive operation even Rambo would think twice about.
The Game-Changer
Then, about 2 years ago, when working on building data lakes as landing zones for cloud-based Enterprise Data Warehouse (EDWs), came the news!
Could that be the tool to bridge the gap between traditional EDWs and Data Lakes?
Two years later, and maybe thousands of implementations globally we can definitely affirm that the gap has been bridged with the release of a new file format: delta.io
Delta brings a host of powerful features to the table. First and most importantly, it supports the ACID properties of transactions, ensuring atomicity, consistency, isolation, and durability of your table data. This is a game-changer for data integrity. Secondly, Delta offers scalable metadata handling with Spark, allowing you to vacuum metadata even on a petabyte scale. This is crucial for managing large datasets efficiently.
But that’s not all. Delta also unifies both streaming and batch data use cases, offering a versatile solution for different data processing needs. It enforces schema rules and allows for schema evolution, providing both stability and flexibility in your data architecture.
One of the most exciting features is time travel. Every operation on a record is automatically versioned in Delta, enabling not just rollback options but also a historical audit trail for your data. This is invaluable for tracking changes and maintaining data quality over time.
Delta also supports merge, update, and delete operations, which are essential for implementing Change Data Capture (CDC) and Slowly Changing Dimension (SCD) methodologies. These features make Delta incredibly versatile for a wide range of data management tasks.
You can find more information here
The Data Lake House: Where your data lives in luxury
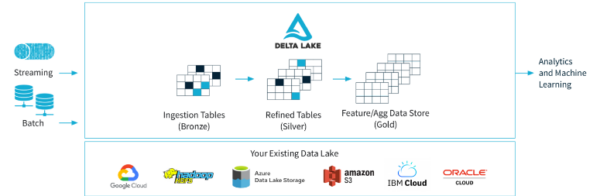
With the introduction of the Delta file format, we’re not just talking about data lakes or data warehouses anymore; we’re talking about a new hybrid: the Data Lake House. Imagine the best of both worlds— the scalability and raw data storage capabilities of a data lake combined with the structured querying and reliability of a data warehouse. That’s your Lake House. It’s a revolutionary concept because it breaks down the barriers between structured and unstructured data, allowing businesses to have their cake and eat it too. You can run real-time analytics and machine learning models directly on raw data without the need for cumbersome ETL processes. In essence, the Lake House offers a unified, cost-effective, and incredibly flexible data architecture that’s poised to become the new gold standard in data management.
Here we are dealing with an OPEN SOURCE file format which unifies the big and the small together, a bit like the String Theory in Modern Physics which intends to find a common model explaining at the same time Quantum and Gravity.
The beauty of the Delta format is that it is a file format with which you could start building your own Lakehouse on the Cloud Service Provider CSP) of your choice as it is now widely supported natively by Azure Data Factory, AWS Glue (3.0), and GCP Dataproc.
I’ll keep the best for the end, instead of using native services from your CSP, you could sit above their Spark Serverless layer and work directly with the tools from the creators of Spark and Delta: Databricks.
Databricks is the de facto Lakehouse platform on the market today. They created Delta and launched it as open source, how about that? Within the Databricks Lakehouse Platform, for once we have a unified environment where the whole Data and Analytics can collaborate and create together. Why? Because the environment has been designed from the ground up to accommodate 3 personas: Data Engineers (building data pipelines), Data Analysts (finding insights in the data) and Data Scientists (solving complex questions with data).
Link to Article: Databricks launches delta lake
So now with one file format unifying lakes and warehouses, we also have one platform unifying the whole Data team as one.
So there you have it, folks. Delta isn’t just an airline or a river; it’s the future of data management. And if you’re looking to build your own Lakehouse, you know who to call…





