










For systems requiring timely and accurate data delivery, whether for the execution of multimillion dollar financial transactions or compliance gating, failure is not an option. Many integration methods still use the outdated “send and retry” pattern, which fails under real-world pressure. Mission-critical systems need more robust solutions.
Today’s systems communicate with each other through polling APIs and events and respond to changes in real time. Strong dependability, security, and data fidelity are more important than ever for your messaging platform, API, or any other target system to guarantee uninterrupted service and reliability. The most crucial thing is how you incorporate into your design features to address the inevitable problems with system availability.
With 15 years of experience in enterprise application development and currently working as an integration developer delivering high-availability solutions for multinational corporations, I have seen firsthand the vulnerability of traditional approaches. I firmly believe that integrations must be constructed from the ground up, emphasizing reliability considerations, such as creating robust frameworks. That’s why, by the end of this post, you’ll see how I’ve applied those principles in real-world systems and walk away with practical, proven approaches to building integrations that don’t just move data, but also protect it.
The following are three challenges I’ve frequently encountered in the mission-critical integration environment, along with the sophisticated design and robust architecture strategies I used to solve them:
- Ensuring critical data reaches external APIs regardless of the circumstances.
- Delivering event data reliably to event platforms.
- Delivering clean, idempotent data from noisy sources.
Challenge 1: Ensure critical data reaches external APIs regardless of the circumstances.
In a past project, I worked with a manufacturing company that needed to send order information to a customer-facing web portal from their ERP system. Sounds simple, right? But one weekend, that portal went down for more than 18 hours. The original integration setup simply kept trying, adding duplicate orders to the system, causing errors all the time, and making a bad situation worse.
Here’s how I made the entire process smarter and self-correcting, inspired by the Circuit Breaker pattern, using Azure Logic Apps, Service Bus Topics, and Subscriptions:
-
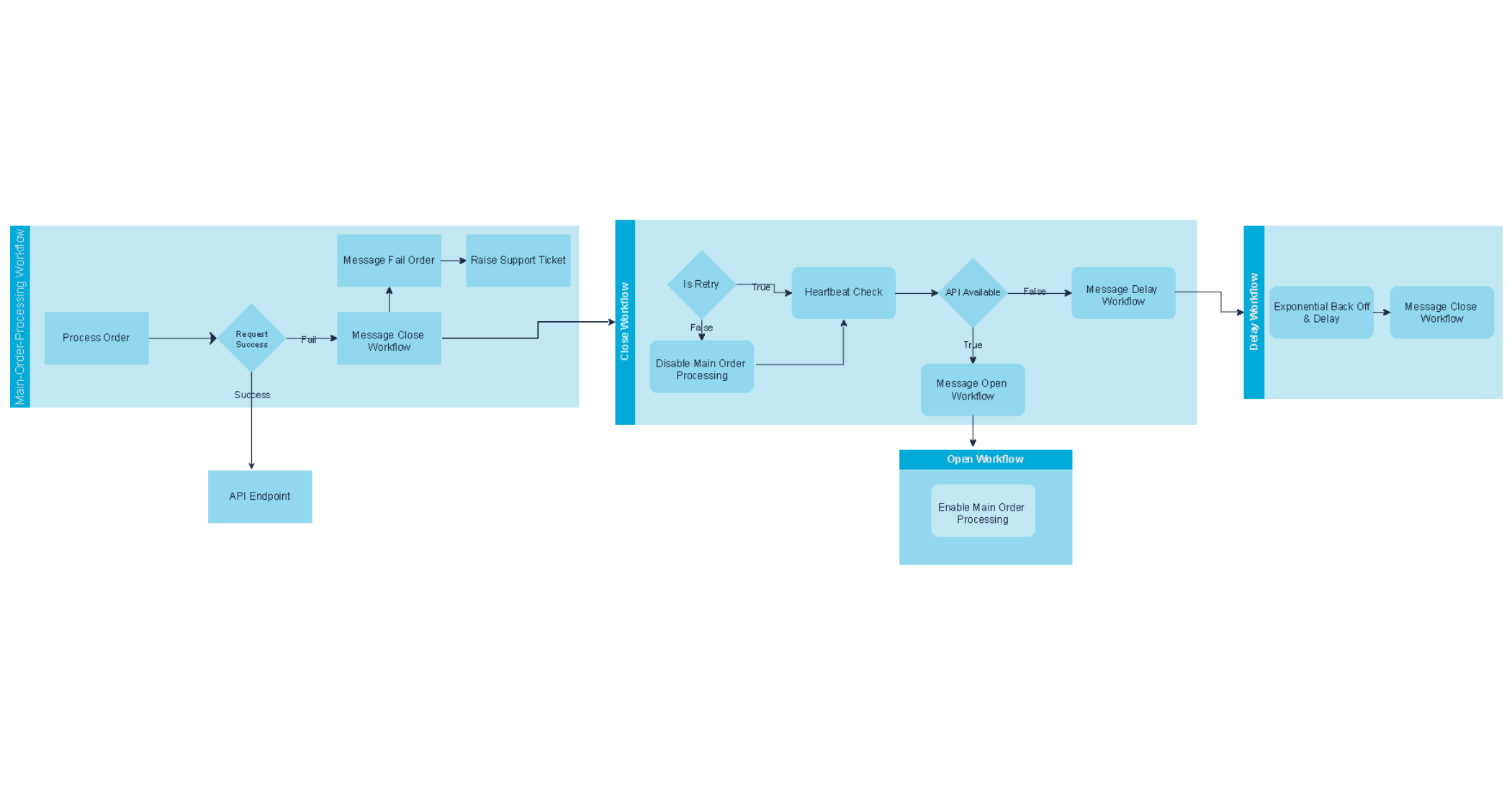
- If the API call fails more than 5 times within the main order-processing workflow, we don’t just keep banging our head against the wall. Instead, the failed message is returned to a Service Bus topic, ready to be retried later when the system is healthy, and the error logging service is notified to raise a support ticket.
-
Trigger a “Close Workflow” to take control of the failure state
- As soon as failures reach that threshold, we trigger a “Close Workflow.” This one accomplishes two things:
- It disables the main order-processing workflow, so we stop sending calls to an unhealthy API.
- Then, rather than continuously checking the API and wasting resources, it uses a different Exponential Backoff Workflow to pause and delay the next check . Once that delay finishes, the Close Workflow will be notified to recheck the API’s status so we know exactly when it will return online without hammering it.
- As soon as failures reach that threshold, we trigger a “Close Workflow.” This one accomplishes two things:
-
Keep customer orders safe while the API is down
- Even with the main order-processing flow disabled, new order messages keep flowing in. They’re safely stored in the Service Bus subscription. Nothing is lost, nothing is duplicated.
-
Bring the Processing Workflow back online automatically
- As soon as the Close Workflow detects the API is back up, it notifies the “Open Workflow.” That one flips the switch and re-enables the main order-processing workflow, automatically sending those queued-up orders again.
-
Exponential Back Off when the API stays down
- If the API is still down after a check, we don’t just keep hammering it. Instead, the Close Workflow notifies the “Exponential Backoff Workflow”. This one pauses for a while before trying again.
- The delay doubles every time it reaches a maximum of four hours, starting small at 1 second, 2 seconds, 4, 8, 16, etc.
- It continues to check every 4 hours until the API returns after it reaches the 4-hour mark.
- Once the delay ends, it loops back and notifies the “Close Workflow” to check again.

With this setup, the whole process becomes resilient and hands-off. No one has to babysit the system. Messages are safe, retries are smart, and the API gets a break while it recovers. Everything will automatically restart when it’s ready.
That’s what I mean by “designing for failure.”
Challenge 2: Deliver Event Data reliably to Event Platforms
In a different project, I collaborated with a financial services organisation that required Azure Event Hub to transmit mortgage applications to their approval system. Each message represented a prospective client waiting for their loan to proceed; these weren’t merely logs or notifications. The applications triggered downstream processing and real-time decision-making. A lost message meant more than just a technical issue; it meant delayed approval, a frustrated applicant, and possibly lost revenue. However, Azure Event Hub experienced occasional glitches, just like any other cloud system. Some messages failed to process due to regional disruptions and intermittent outages.
I designed a flow inspired by the Outbox pattern, using Logic Apps, Azure Event Hub, and Azure SQL database to make sure everything would work no matter what.
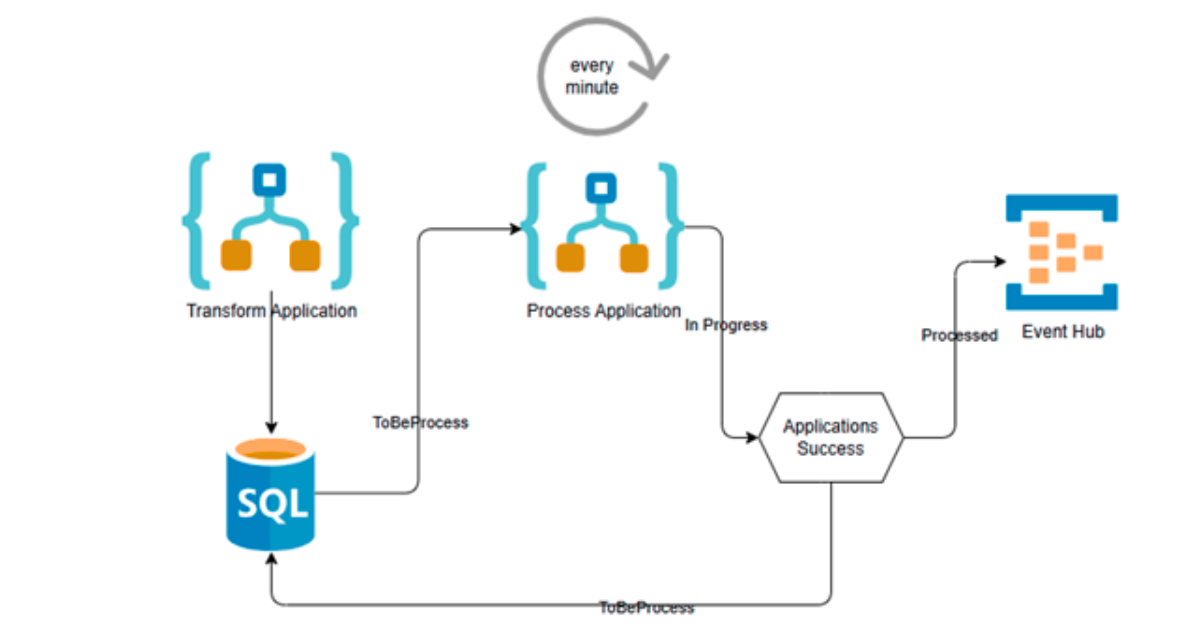
Here’s how the flow works:
-
Transform and store first
- A Logic App converts a new mortgage application according to the approval system’s schema and saves it in a database with the status “ToBeProcessed”.
-
Recurring processing loop
- Using a one-minute recurrence trigger, a second Logic App workflow searches the database for records marked as “ToBeProcessed”.
- If it finds records, it marks them as “In Progress”, sends them individually to Azure Event Hub and awaits confirmation.
-
Guaranteed delivery and status tracking
- The record is marked as “Processed” if the message is sent successfully.
- However, the Logic App rolls the record back to “ToBeProcessed” if Azure Event Hub is unavailable for any reason, such as a network blip, outage, etc.
-
Automatic retries without human involvement
- On the next run (just a minute later), the system picks that record up again and tries sending it.
- This cycle continues until the message is successfully delivered; no data is lost in the cracks, and no human monitoring is required.
This method eliminates the hassle of handling dead-letter queues and manual replays by relying on straightforward state tracking in the database. This gives us complete visibility into what has been processed and what is pending. It’s reliable, scalable, and ideally suited for high-stakes data like mortgage applications. It assured the company that each application was processed precisely as planned.
Challenge 3: Deliver clean, idempotent data from noisy sources.
As part of a project with a manufacturing client, we had to transfer customer, product, and order information from their ERP system to a customer-facing web portal. It should have been simple until we ran into an issue.
We frequently received the same record from the ERP system more than once, which caused duplicates to overflow the system. Messages arrived in Azure Service Bus, but Service Bus’s built-in duplication detection could not detect them since each message had a distinct message ID and somewhat different metadata. As a result, the web portal ended up with duplicate customer, product and order entries, causing confusion and clutter for users.
Here’s how I re-architected the flow, inspired by the Inbox pattern, using Logic Apps, and Azure SQL database to prevent duplication:
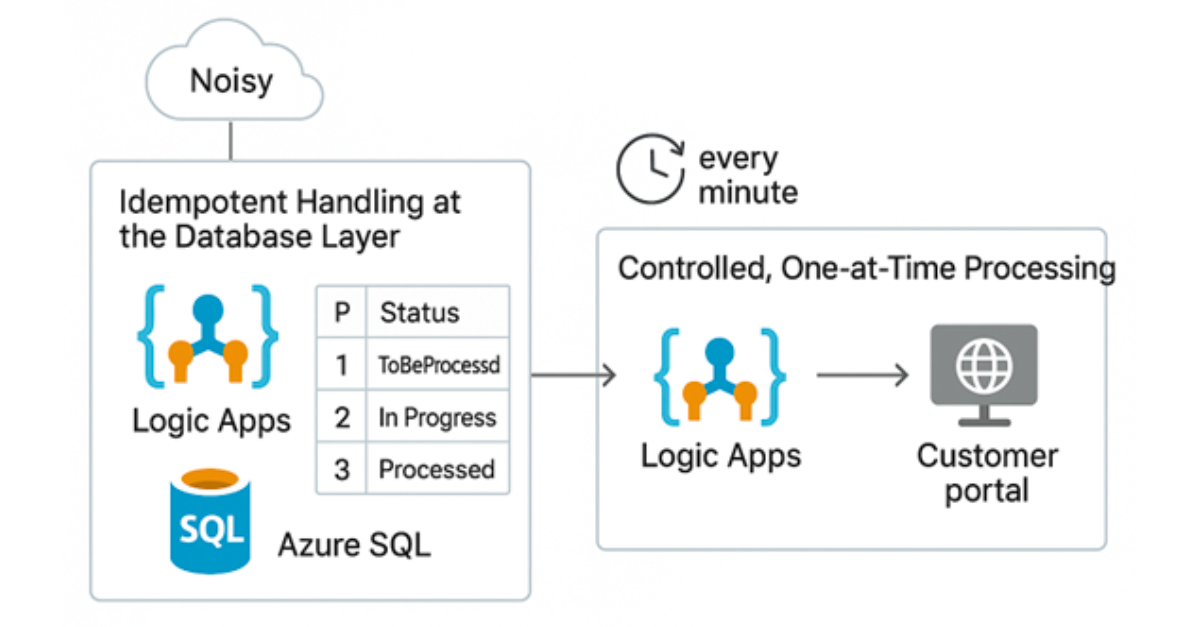
-
Idempotent Handling at the Database Layer
- Every message is received by a Logic App workflow and stored in a SQL database.
- It looks for an existing record with the same primary key and the status “ToBeProcessed” before inserting.
- If it does, the existing record is updated.
- Otherwise, a new record with the status “ToBeProcessed” is added.
-
Controlled, one-at-a-time processing
- A second Logic App workflow, triggered every minute, looks for records marked “ToBeProcessed”.
- If it finds records, it marks them as “In Progress”; each is processed and delivered to the customer portal.
- After a successful send, the record’s status is changed to ”Processed”.
-
Clean output, even with noisy input
- Even if the ERP system sends duplicate records, this method ensures that only one version is ever processed and delivered.
This solution removes downstream duplication, gives complete control and visibility over the integration pipeline, and doesn’t require any modifications to the upstream ERP system. It maintains the customer portal as it should be accurate, noise-free, and clean.
Conclusion
Throughout this post, I’ve discussed three actual integration problems, all of which are influenced by the fact that tools alone don’t always ensure success. How you design your systems to handle failure, manage complexity, and deliver reliability under pressure matters.
In Challenge 1, I addressed the need for fault tolerance when working with unreliable external APIs. I created workflows that could recognise outages, pause automatically, and resume only when safe, without overloading the API or losing data.
In Challenge 2, I handled mortgage applications with great care, kept track of their progress in a database, and verified that everything was delivered successfully before marking anything as processed.
In Challenge 3, I implemented database-level logic to handle duplicate messages from an ERP system, ensuring that only clean, unique instances ever reached the customer portal.
The guiding principles behind creating each of these solutions were designed for failure, automating recovery, and never depending on “ideal conditions.” What does this mean for your business? Reliability is necessary if your systems manage data that influences transactions, compliance, or customer satisfaction. Resilient integration means:
- Building workflows that self-heal and adapt to failure.
- Using smart retry and state-based processing instead of blind retries.
- Preventing data loss, duplication, or inconsistency
- Supporting 24/7 operations without constant manual oversight
Over the years, I’ve built systems across industries that needed to work under pressure, recover gracefully, and scale without breaking. That experience taught me that integration isn’t just about wiring systems together. It’s about thoughtfully and intentionally designing the data flow through them. And often, that matters more than the tools themselves.




